导言
大多数与图像识别相关的分类问题都存在着众所周知的/既定的问题。例如,通常情况下,没有足够的数据来对分类系统进行适当的训练,这些数据涵盖的类可能会有所不足,而且最常见的情况是,使用未经仔细检查的数据将意味着我们对数据的标签缺乏合理的分类。


数据是决定你的努力是失败还是成功的关键。这些系统不仅仅需要比人类更多的数据来学习和区分不同的类,它们还需要成千上万倍的数据才能相对较好的完成这项工作。
深度学习依靠大量高质量的数据来预测未来的趋势和行为模式。并且数据集需要代表我们打算预测的类,否则,系统会”曲解”不同类的分布,让你的模型产生偏差。
这些问题通常有一个共同的原因:即查找、提取和存储大量数据的能力不够强大,以及在第二层上对数据的清除、管理和处理能力不足。
虽然我们可以提高计算能力和数据存储能力,但这种情况只有当这是一个复杂的、大的卷积神经网络针对一个大的数据集运行时才会考虑,只有一台机器是不可能的。因为它可能没有足够的空间/内存,而且很可能没有足够的计算能力来运行分类系统。它还需要通过云资源”访问”并行或分布式计算,了解如何运行、组织和设置复杂的集群。
然而,拥有足够的数据和处理能力并不足以防止这些问题的发生。
在这篇文章中,我们将探索和讨论一些不同的技术,这些技术可以解决在处理小数据集时出现的问题,如缓解分类的不平衡,以及如何防止过度拟合。
迁移学习
“数据可能是新的煤炭”,引用自NeilLawrence的话。我们知道深度学习算法需要通过大量的标记数据从零开始训练一个成熟的网络,但是我们常常无法完全理解大量这个词意味着多少数据。简单来说,仅仅是找到满足你训练需求的数据量可能都会给你带来挫折感,但是有一些技术,例如数据增强或迁移学习,将为你的模型节省大量的精力和时间。
迁移学习是一种流行的、非常强大的方法,简而言之,它可以概括为是把已训练好的模型参数迁移到新的模型来帮助新模型训练。这意味着利用现有的模型并改变它以适应你自己的目标。这种方法包括”切断”前训练模型的最后几个层,并使用你的数据集对它们进行再训练。这样做有以下优点:
它在较老的模型上建立了一个新的模型,并对图像分类任务进行了验证。例如,一个建立在CNN体系架构上的模型(比如由Google开发的CNN模型Inception-v3),然后经过ImageNet的预训练;
它减少了训练时间,因为它允许重复使用参数以实现可能需要数周才能达到的性能。
不平衡数据
通常,数据集中的一组标签相对于其他数据集中的标签的比例可能是不平衡的,而这个时候,所占比例较低标的标签组往往是我们感兴趣的一组,因为它相对稀有。例如,假设我们有一个二进制分类问题,X类代表95%的数据,Y类代表其他5%的数据。因此,该模型对X类更”敏感”,对Y类不太”敏感”。当分类器的准确率达到95%时,我们只能说对X类的预测基本都是正确的。
显然,这里的准确性不是一个适当的”评分”。在这种情况下,我们更应该考虑的是预测错误的代价、预测精确度和查全率。一个合理的起点是对不同类型错误的二维表示,换句话说,是一个混淆矩阵。在本文中,可以将其描述为说明实际标签与预测标签的方法,如下图所示。
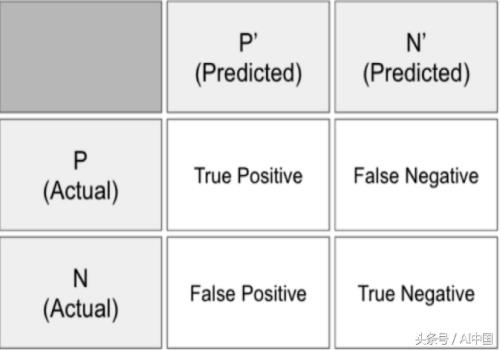
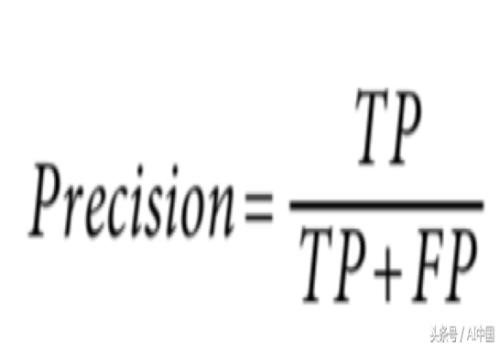
通过存储从模型预测中获取的真阳性、假阳性、真阴性和假阴性的每个标签的个数,我们可以使用查全率和精确性来估计每个标签的性能。精度的定义是:
查全率在比率中定义为:
查全率/精确性会暴露出分类不平衡的问题,但并不能解决它。但是,有一些方法可以缓解分类不平衡的问题:
通过给每个标签分配不同的系数;
通过对原始数据集进行重新采样,或者对少数类进行过采样或对多数类进行过采样。也就是说,由于分类边界的更”严格”,数据集太小容易带来误差,让过采样更容易导致过度拟合。
通过应用SMOTE方法(对少数过采样进行合成的技术)来解决频繁对分类数据进行复制的问题。该方法在数据增强的背后应用了相同的思想,并通过在少数类的相邻实例之间插值来创建新的合成样本。
过度拟合
正如我们所知,我们的模型通过反向传播和最小化成本函数来学习/概括数据集中的关键特性。每一个来回的步骤都被称为一个轮次,并且随着每一个轮次的调整进行模型的训练和权值的更改,以最小化错误的代价。为了测试模型的准确性,一个常见的规则是将数据集分为训练集和验证集。
训练集用于调整和创建模型,让模型更加符合训练前的目的。验证集测试基于不可见样本模型的有效性。
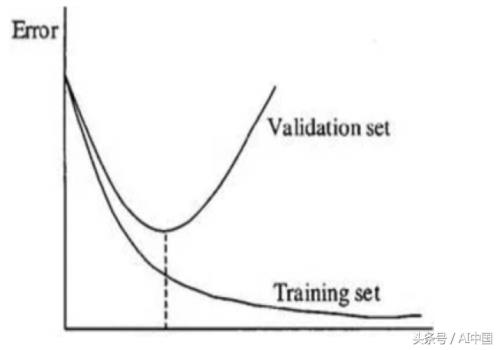
尽管对实际情况的错误验证会让曲线图有更大的起伏。
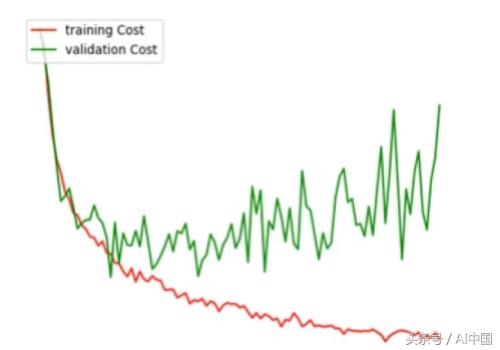
在每一个轮次结束时,我们用验证集测试模型,在某个点上,模型开始记忆训练集中的特征。当我们到达某个阶段时,发现验证集上频繁的发生错误并且精度变差,这说明模型是过度拟合的。
选择网络的大小和复杂程度将是过度拟合的决定性原因。复杂的体系结构可能更容易过度拟合,但是,有一些策略可以防止过度拟合:
增加训练集上的样本数量;如果对网络进行更多实际案例的训练,它将具有更好的普遍性;
当过拟合发生时,停止反向传播是另一种选择,这样可以保证成本函数和验证集的准确性;
采用正则化的方法是另一个流行的选择。
L2正则化
L2正则化是一种通过向较大的个体权重进行分配约束来降低模型复杂度的方法。通过设置惩罚约束,减少模型对训练数据的依赖。
Dropout
对于正则化来说,Dropout也是一种常见的选择,它被用于较高层的隐藏单元上,然后我们为每个轮次建立了不同的架构。基本上,该系统随机选择要在训练中去除的神经元,通过不断地重新调整权重,网络被迫从数据中学习更普遍的模式。
结语
正如我们所看到的,有各种不同的方法和技术来解决图像识别中最常见的分类问题,每种方法和技术都有各自的优点和潜在的缺点。存在的一些问题是数据不平衡,过度拟合,其中最通常的问题是不会有足够的数据可用,但是,正如我们已经解释过的,它们可以通过迁移学习、抽样方法和正则化技术来解决。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,请发送邮件至 55@qq.com 举报,一经查实,本站将立刻删除。转转请注明出处:https://www.szhjjp.com/n/31044.html