今天来跟大家分享用 BeautifulSoup 获取信息的一些知识点,文章内容由公众号读者 Peter 创作。
欢迎各位童鞋向公众号投稿,点击下面图片了解详情!
爬虫,是学习Python的一个有用的分支,互联网时代,信息浩瀚如海,如果能够便捷的获取有用的信息,我们便有可能领先一步,而爬虫正是这样的一个工具。
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库。由于 BeautifulSoup 是基于 Python,所以相对来说速度会比另一个 Xpath 会慢点,但是其功能也是非常的强大,本文会介绍该库的基本使用方法,帮助读者快速入门。
网上有很多的学习资料,但是超详细学习内容还是非官网莫属,资料传送门:
英文官网:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
中文官网:
https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
本文的主要内容如下:
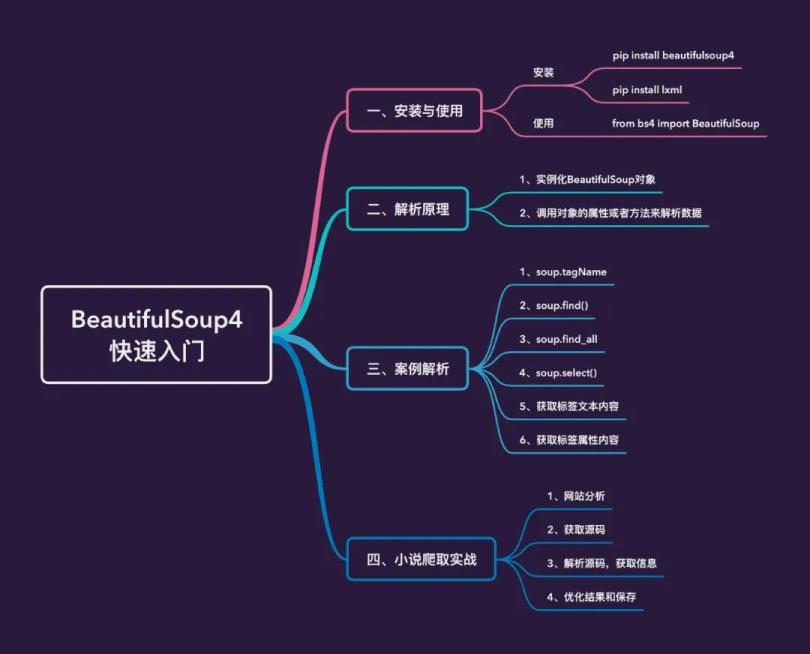

安装和使用
安装
安装过程非常简单,直接使用pip即可:
pip install beautifulsoup4
上面安装库最后的4是不能省略的,因为还有另一个库叫作 beautifulsoup,但是这个库已经停止开发了。
因为BS4在解析数据的时候是需要依赖一定的解析器,所以还需要安装解析器,我们安装强大的lxml:
pip install lxml
在python交互式环境中导入库,没有报错的话,表示安装成功。

使用
使用过程直接导入库:
from bs4 import BeautifulSoup
解析原理
解析原理
- 实例化一个BeautifulSoup对象,并且将本地或者页面源码数据加载到该对象中
- 通过调用该对象中相关的属性或者方法进行标签定位和数据提取
如何实例化BeautifulSoup对象
- 将本地的HTML文档中的数据加载到BS对象中
- 将网页上获取的页面源码数据加载到BS对象中
案例解析
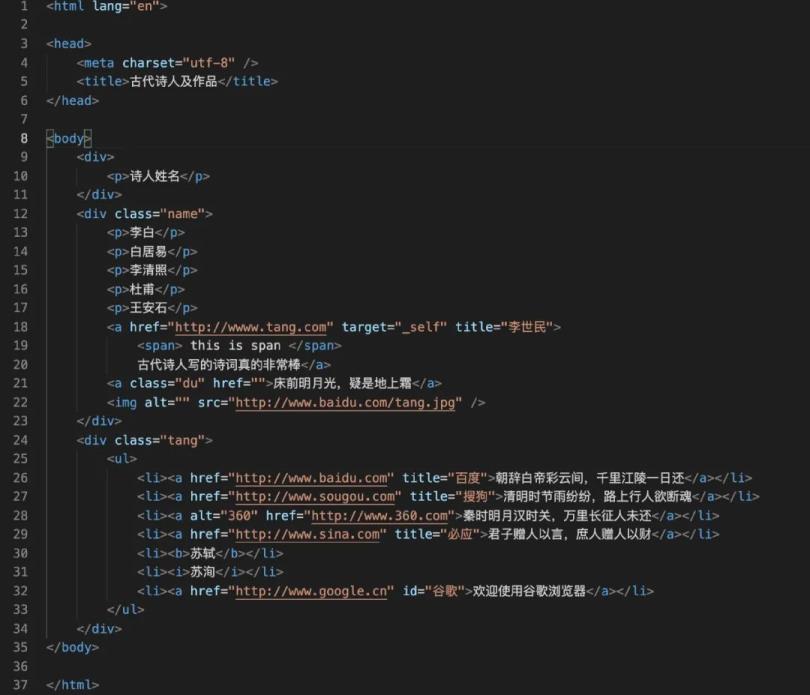
原数据
假设我们现在本地有一个HTML文件待解析,具体内容如下,数据中有各种HTML标签:html、head、body、div、p、a、ul、li等
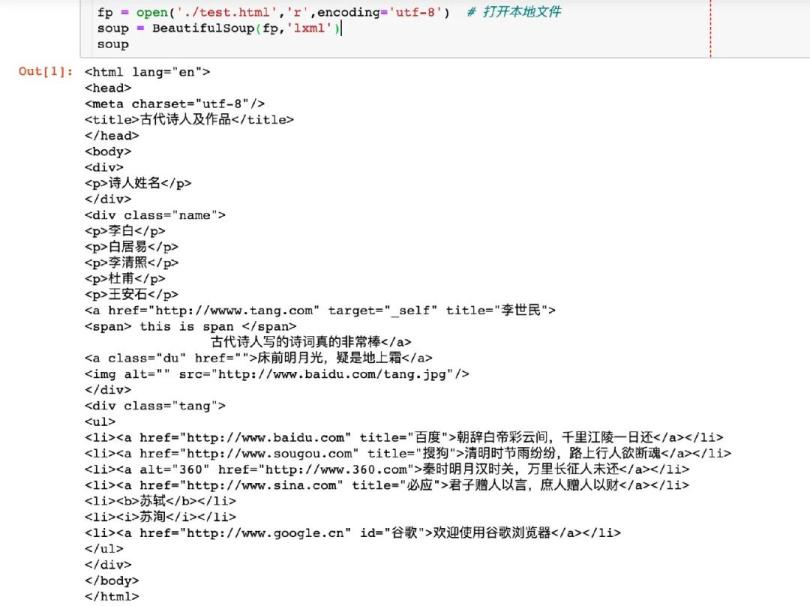
加载数据
from bs4 import BeautifulSoup
fp = open(\'./test.html\',\'r\',encoding=\'utf-8\') # 打开本地文件
soup = BeautifulSoup(fp,\'lxml\')
soup
所有的数据解析都是基于soup对象的,下面开始介绍各种解析数据方法:
soup.tagName
soup.TagName返回的是该标签第一次出现的内容,以a标签为例:
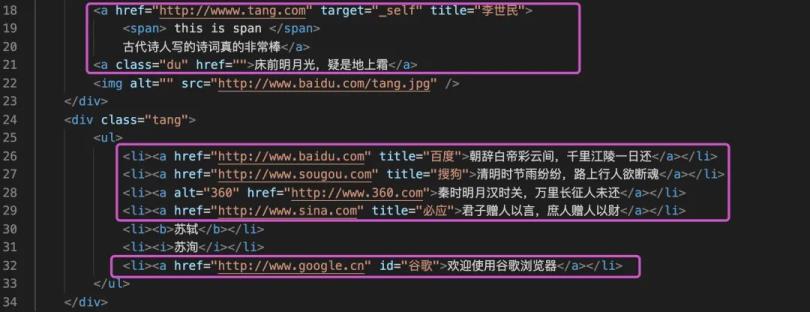
数据中多次出现a标签,但是只会返回第一次出现的内容

我们再看下div标签:
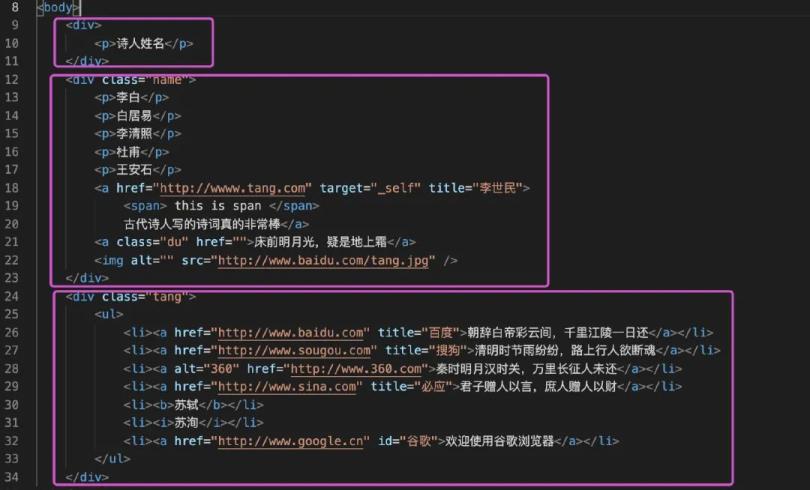
出现了2次,但是只会返回第一次的内容:

soup.find(‘tagName’)
find()主要是有两个方法:
- 返回某个标签第一次出现的内容,等同于上面的soup.tagName
- 属性定位:用于查找某个有特定性质的标签
1、返回标签第一次出现的内容:
比如返回a标签第一次出现的内容:

再比如返回div标签第一次出现的内容:
2、属性定位
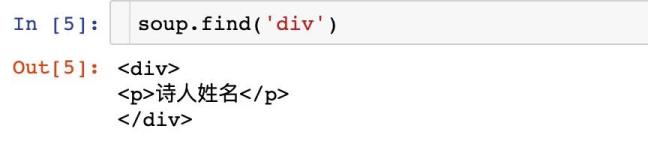
比如我们想查找a标签中id为“谷歌”的数据信息:

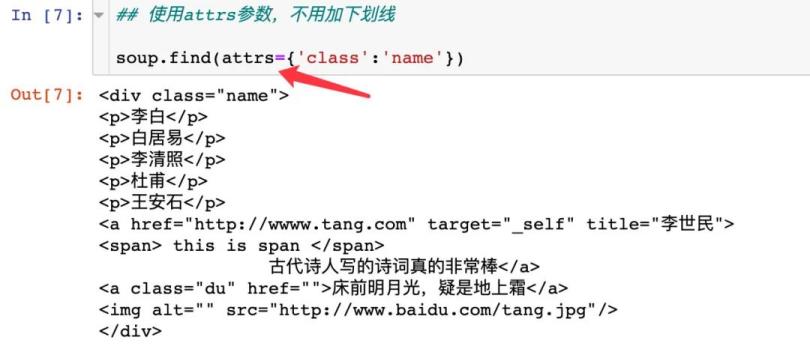
在BS4中规定,如果遇到要查询class情况,需要使用class_来代替:

但是如果我们使用attrs参数,则是不需要使用下划线的:
soup.find_all()
该方法返回的是指定标签下面的所有内容,而且是列表的形式;传入的方式是多种多样的。
1、传入单个指定的标签

image-20210523170401516
上面返回的是列表形式,我们可以获取我们想要的内容:

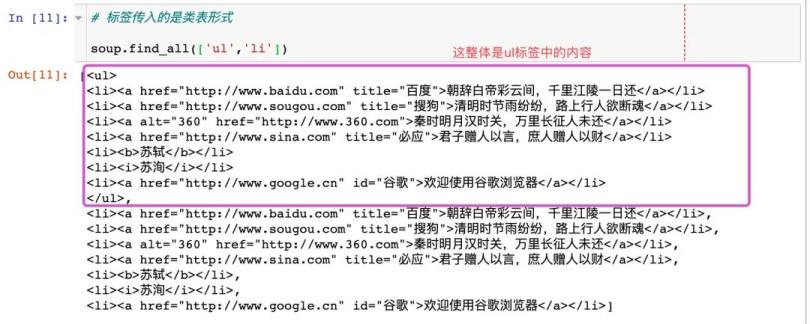
2、传入多个标签(列表形式)
需要主要返回内容的表达形式,每个标签的内容是单独显示的
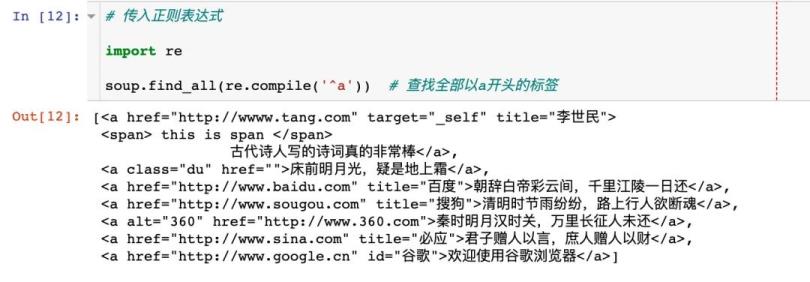
3、传入正则表达式
比如查看以a开头标签的全部内容
查看以li标签开头的全部内容:

选择器soup.select()
主要是有3种选择器,返回的内容都是列表形式
- 类选择器:点
- id选择器:#
- 标签选择器:直接指定标签名
1、类选择器

2、id选择器


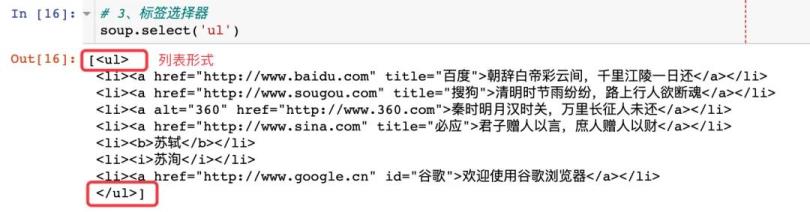
3、标签选择器
直接指定li标签
4、选择器和find_all()可以达到相同的效果:

soup.tagName和soup.find(‘tagName’)的效果也是相同的:

层级选择器使用
在soup.select()方法中是可以使用层级选择器的,选择器可以是类、id、标签等,使用规则:
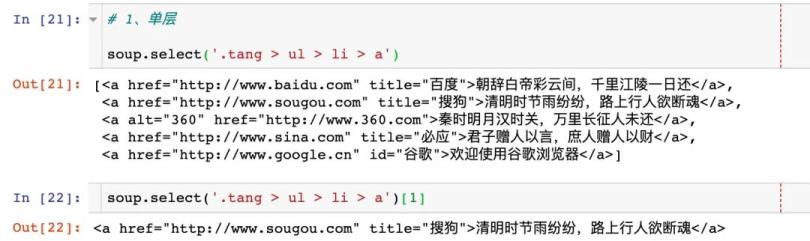
- 单层:>
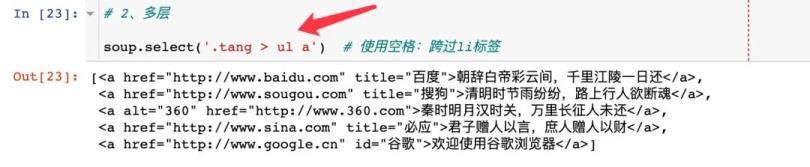
- 多层:空格
1、单层使用
2、多层使用
获取标签文本内容
获取某个标签中对应文本内容主要是两个属性+一个方法:
- text
- string
- get_text()
1、text
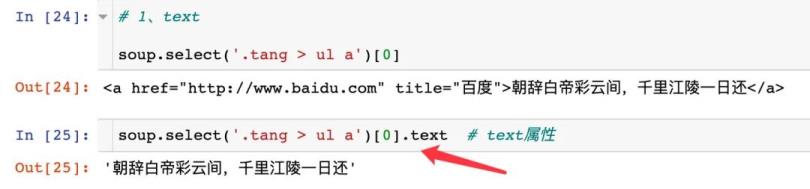
2、string

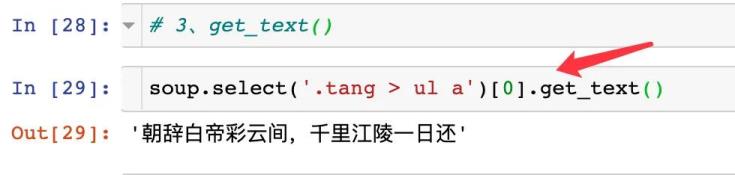
3、get_text()
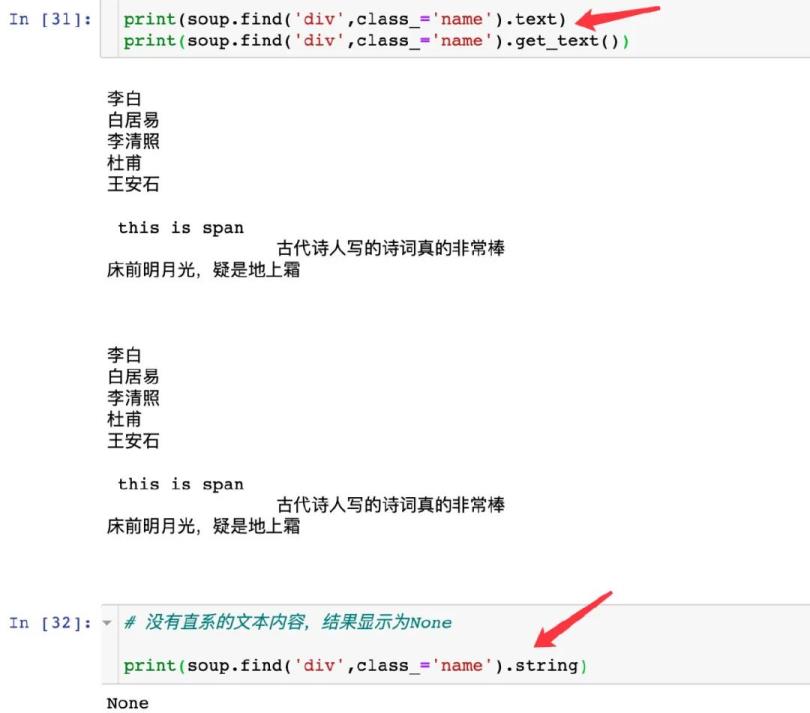
3者之间的区别
# text和get_text():获取标签下面的全部文本内容
# string:只能获取到标签下的直系文本内容
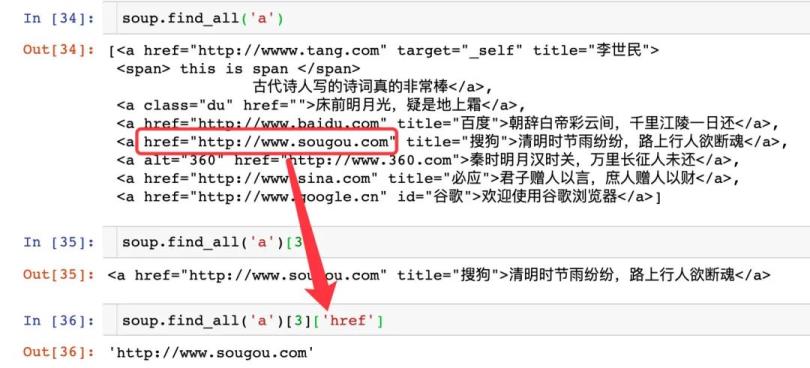
获取标签属性值
1、通过选择器来获取

2、通过find_all方法来获取
BeautifulSoup实战
下面介绍的是通过BeautifulSoup解析方法来获取某个小说网站上古龙小说名称和对应的URL地址。
网站数据
我们需要爬取的数据全部在这个网址下:
https://www.kanunu8.com/zj/10867.html,右键“检查”,查看对应的源码,可以看到对应小说名和URL地址在源码中位置
每行3篇小说在一个tr标签下面,对应的属性href和文本内容就是我们想提取的内容。
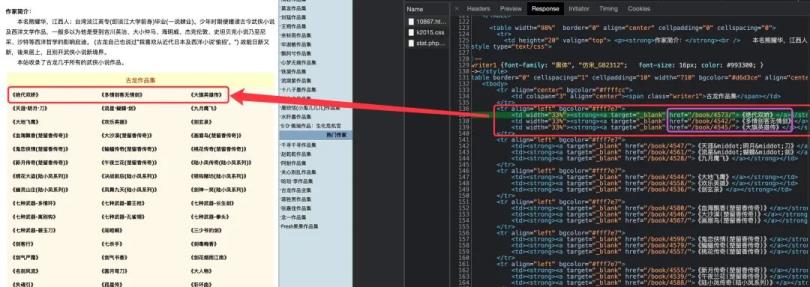
获取网页源码
import requests
from bs4 import BeautifulSoup
import pandas as pd
import re
url = \'https://www.kanunu8.com/zj/10867.html\'
headers = {\'user-agent\': \'个人请求头\'}
response = requests.get(url = url,headers = headers)
result = response.content.decode(\'gbk\') # 该网页需要通过gbk编码来解析数据
# result
实例化BeautifulSoup对象
soup1 = BeautifulSoup(result,\'lxml\')
# print(soup1.prettify()) 美化输出源码内容
获取名称和URL地址
1、先获取整体内容
两个信息全部指定a标签中,我们只需要获取到a标签,通过两个属性href和target即可锁定:
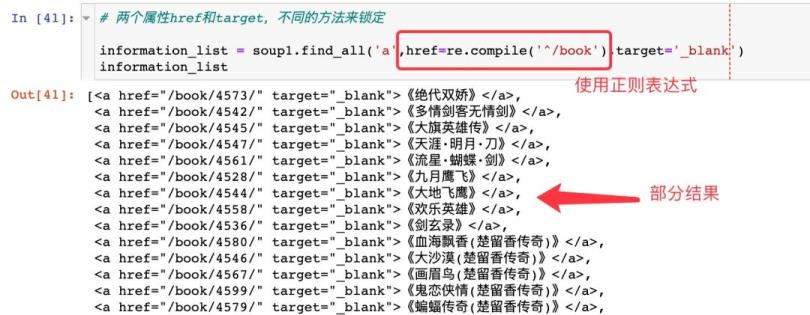
# 两个属性href和target,不同的方法来锁定
information_list = soup1.find_all(\'a\',href=re.compile(\'^/book\'),target=\'_blank\')
information_list
2、再单独获取两个信息
通过属性来获取URL地址,通过文本来获取名称
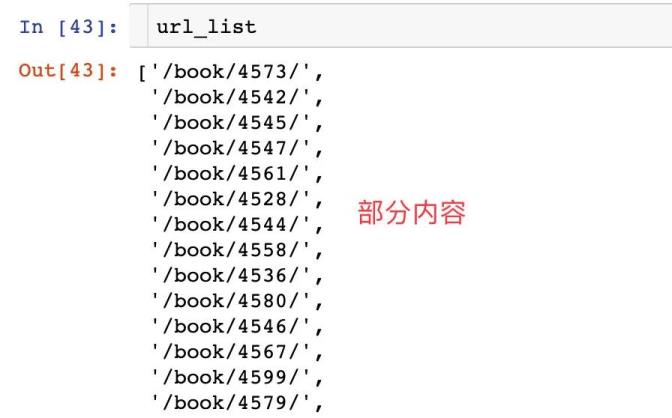
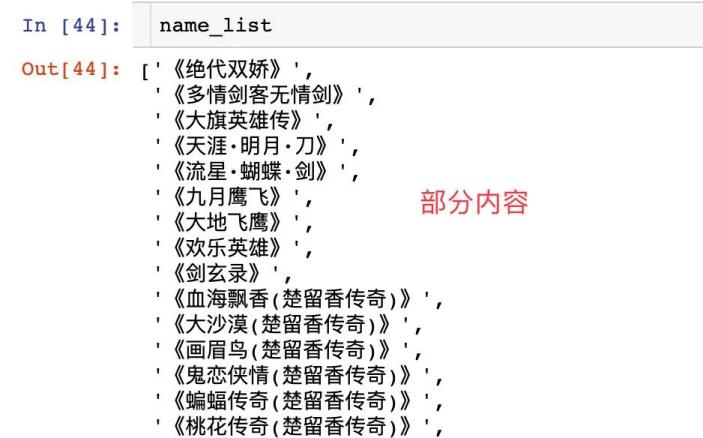
url_list = []
name_list = []
for i in information_list:
url_list.append(i[\'href\']) # 获取属性
name_list.append(i.text) # 获取文本
3、生成数据帧
gulong = pd.DataFrame({
\"name\":name_list,
\"url\":url_list}
)
gulong
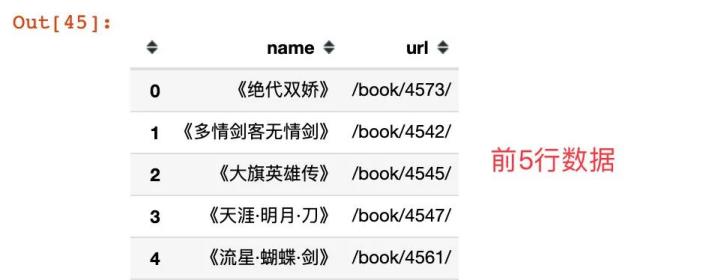
我们发现每部小说的具体地址其实是有一个公共前缀的:
https://www.kanunu8.com/book,现在给加上:
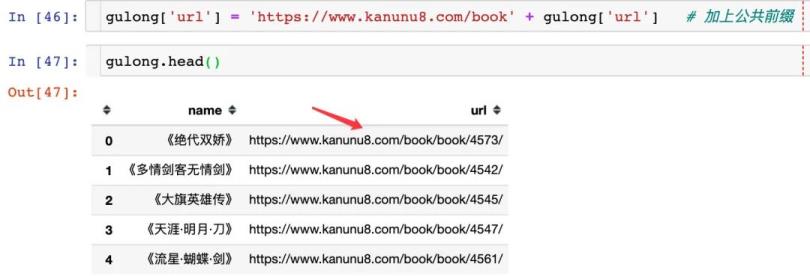
gulong[\'url\'] = \'https://www.kanunu8.com/book\' + gulong[\'url\'] # 加上公共前缀
gulong.head()
另外,我们想把书名的《》给去掉,使用replace替代函数:
gulong[\"name\"] = gulong[\"name\"].apply(lambda x:x.replace(\"《\",\"\")) # 左边
gulong[\"name\"] = gulong[\"name\"].apply(lambda x:x.replace(\"》\",\"\")) # 右边
# 保存
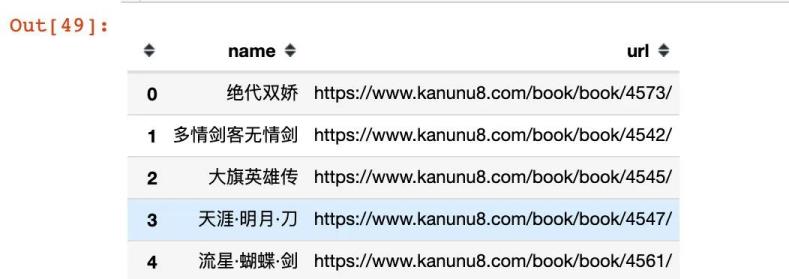
gulong.to_csv(\"gulong.csv\",index=False) # 保存到本地的csv文件
最后显示的前5行数据:
总结
本文从BeautifulSoup4库的安装、原理以及案例解析,到最后结合一个实际的爬虫实现介绍了一个数据解析库的使用,文中介绍的内容只是该库的部分内容,方便使用者快速入门,希望对读者有所帮助。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,请发送邮件至 55@qq.com 举报,一经查实,本站将立刻删除。转转请注明出处:https://www.szhjjp.com/n/26116.html